

扫一扫
分享文章到微信
扫一扫
关注官方公众号
至顶头条
本部分是本系列RNN教程的最后一部分。错过前三部分的可点击以下文字链接进行回顾:
1.循环神经网络(RNN)的基本介绍
2.在Python和Theano框架下实现RNN
3.基于时间的反向传播算法和梯度消失问题

今天,我们将详细介绍LSTM(长短时记忆)神经网络和GRU(门控循环单元)。LSTM于1997年由Sepp Hochreiter 和Jürgen Schmidhuber首次提出,是当前应用最广的NLP深度学习模型之一。GRU于2014年首次被提出,是LSTM的简单变体,两者有诸多共性。
先来看看LSTM,随后再探究LSTM与GRU的差异。
我们在第三部分的教程中提到过梯度消失问题是如何阻碍标准RNN学习长期依赖的。而LSTM就是通过引入一个叫做“门”(gating)的机制来缓解梯度消失问题。为了更好的理解这一问题,不妨先看看LSTM是如何计算隐藏层s_t的:

▲LSTM计算式子
这些式子看似复杂,实则不难。首先,我们要注意LSTM层仅仅是计算隐藏层的另一种方式。
在传统的RNN中,我们用s_t = tanh(Ux_t + Ws_)这个式子来计算隐藏层。其中,隐藏层的输入单元有两个,一个是当前时刻t的输入x_t以及前一时刻的隐藏状态s_。LSTM单元的功能与之相同,只是方式不同而已。这是理解LSTM的关键。你基本上可将LSTB(和GRU)单元视为黑匣子,只要你给定当前输入和前一时刻的隐藏状态,便可计算出下一隐藏状态。如下图:
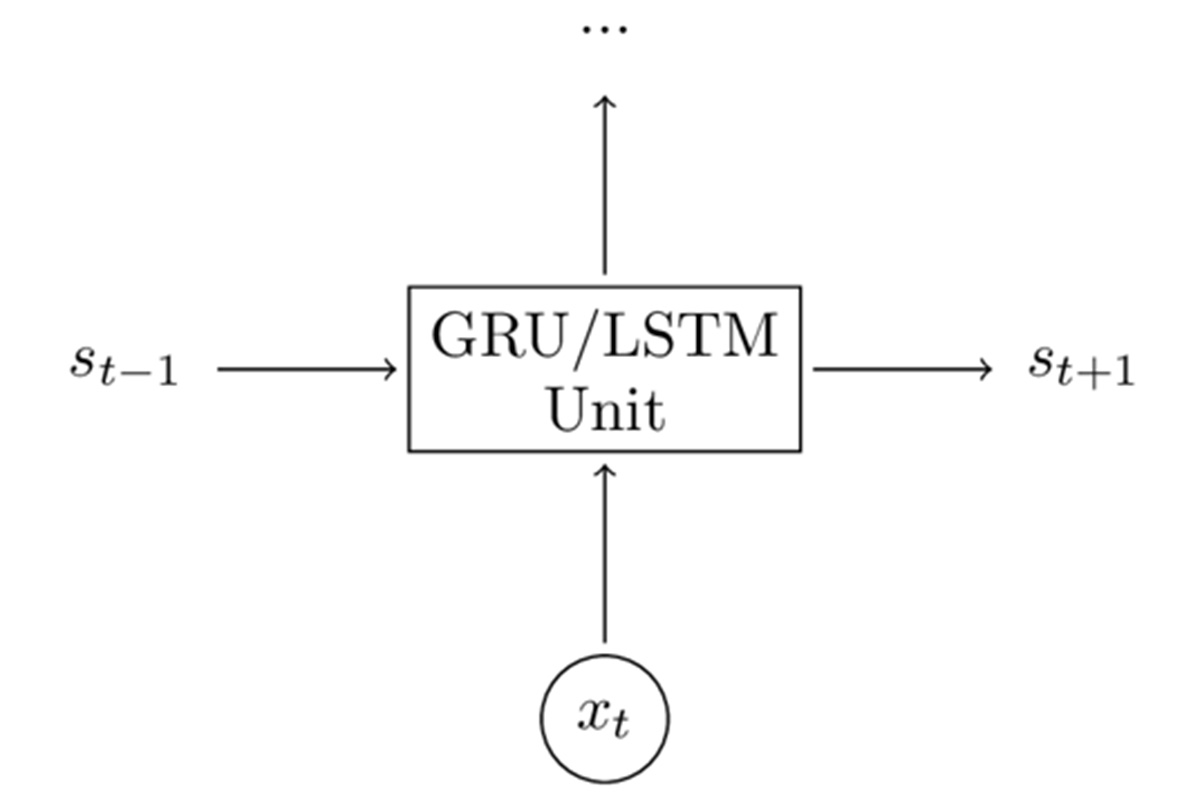
▲简化LSTM和GRU模型
了解这一点后,就可以来看看LSTM单元中隐藏层的计算方法了。Chris Olah的一篇博文详细介绍过这一点(http://colah.github.io/posts/2015-08-Understanding-LSTMs/),此处不作赘述,仅简单介绍。
总结如下:
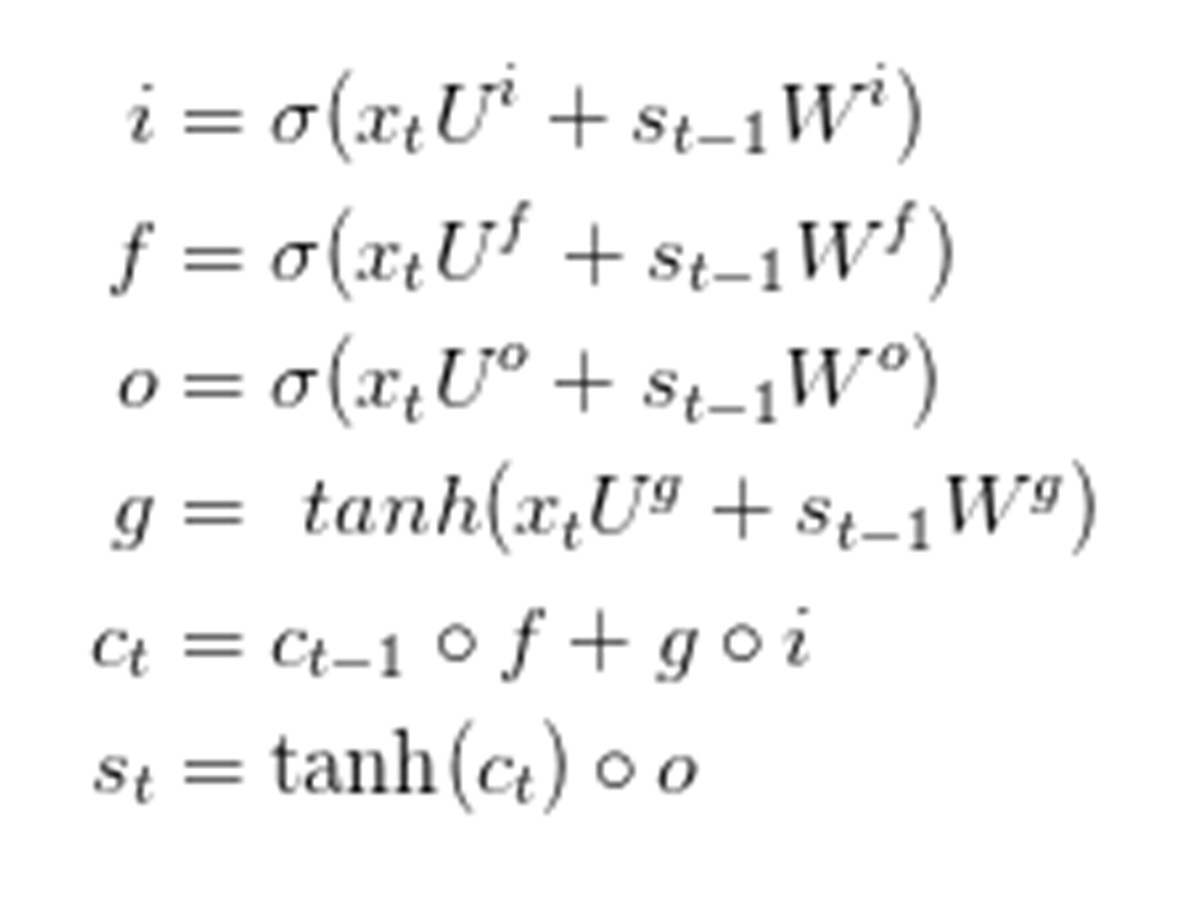
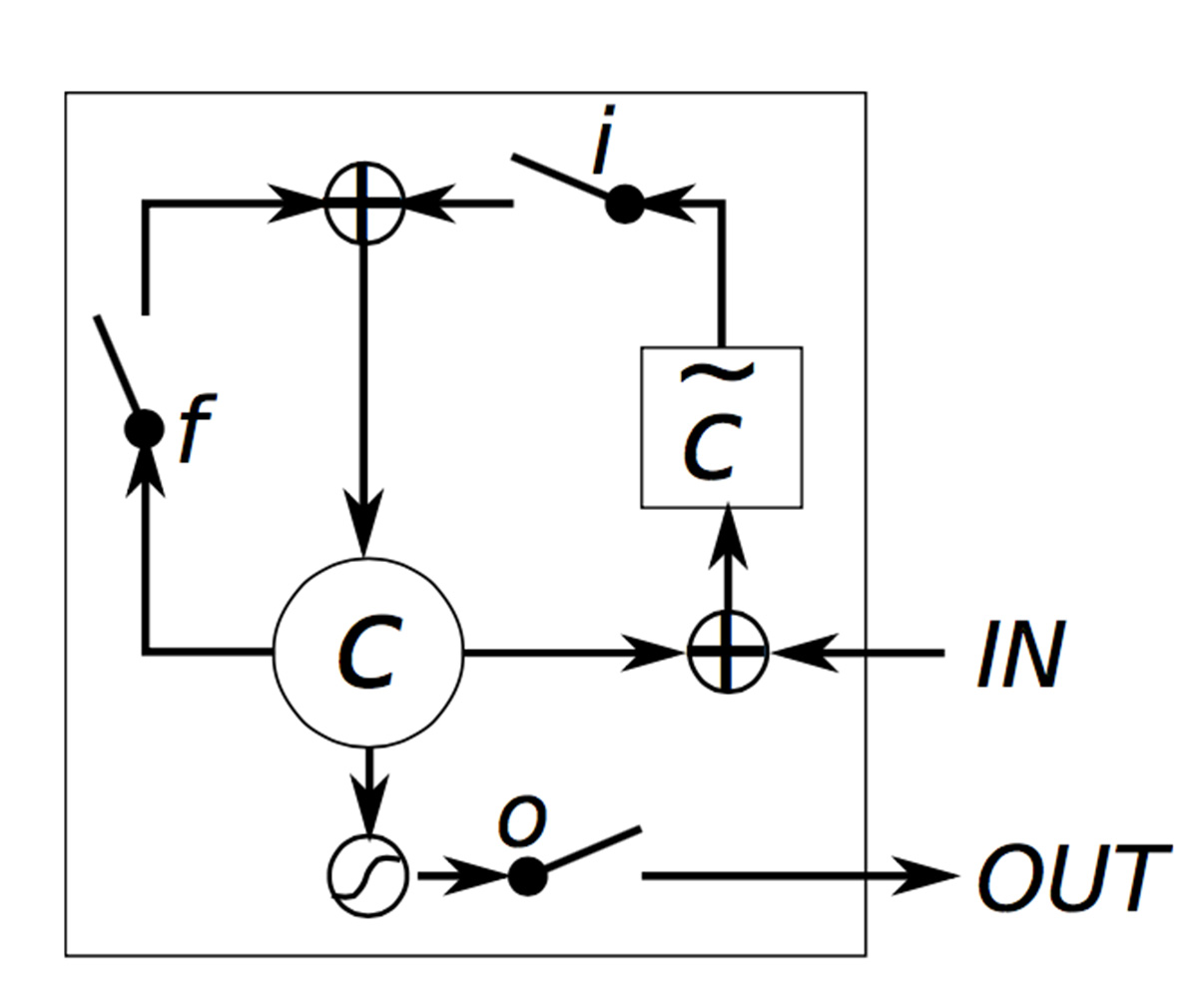
▲LSTM的内部细节
图片来源:“Empirical evaluation of gated recurrent neural networks on sequence modeling.” Chung, Junyoung等著。
直观上,传统的RNN可视作LSTM的一个特殊情况。即当我们把所有输入门固定为1,所有忘记门固定为0(即永远忽略前一时刻的记忆单元),所有输出门固定为1(即呈现所有记忆),就近乎得到了标准的RNN,只不过多出一个附加的tanh,缩小了输出范围。正是这个“门机制”让LSTM可以明确建立长期记忆以来的模型,通过学习这些“门”的参数,神经网络能够更好地学习如何利用这些记忆。
显然,基础LSTM架构也有几种变体。最常见的变体是创建了窥视孔(peephole)连接,使“门”不仅仅取决于前一时刻的隐藏状态s_和前一时刻的内部记忆单元c_,并在“门”的方程中增加了附选项即可。当然,LSTM还有更多变体。这篇论文(LSTM: A Search Space Odyssey)做了更详述的介绍,如有需要可供参考。
GRU网络的原理与LSTM非常相似,方程式也几乎相同,如下:
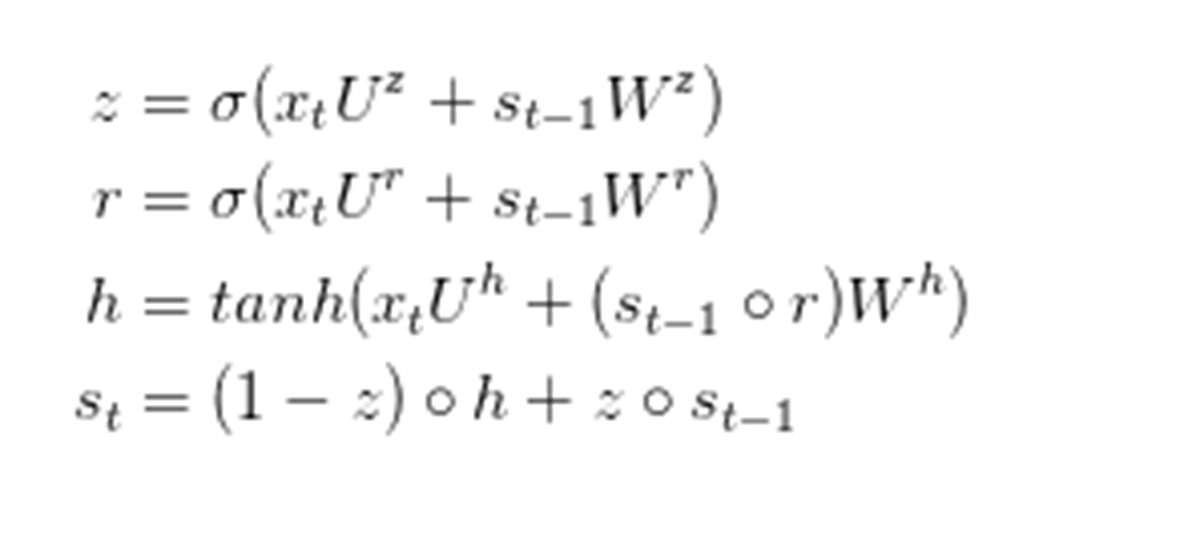
▲GRU计算式子
GRU有两个门:重置(reset)门r和更新(update)门z。直观来讲,重置门决定了新的输入与前一时刻记忆的组合方式,更新门则决定了先前记忆信息的保留程度。如果将所有重置门设为1,所有更新门设为0,即可再次得到传统的RNN模型。
我们发现,GRU中用门机制来实现学习长期记忆的基本原理与LSTM相同,但也有一些区别:

▲GRU内部细节
图片来源:“Empirical evaluation of gated recurrent neural networks on sequence modeling.” Chung, Junyoung等人于2014年著。
现在,我们已经了解了解决RNN梯度消失问题的两种模型,但可能还不清楚应该使用哪一种模型。
具体来看,GRU仍处于初级阶段(于2014年提出),关于它的一些利弊现在还没有探索清楚。
但事实上,这两种模型在许多任务中都不相上下,因此,与挑选出一个理想的架构相比,调整层数这些超参数等更重要。
GRU的参数较少(U和W都较小),因此其训练速度更快,或需要归纳的数据更少。相对应的,如果有足够的训练数据,表达能力更强的LSTM或许效果更佳。
现在我们借助GRU来实现第二部分中的语言模型(LSTM也差不多,只是式子不同而已)。
我们基于之前Theano版本的代码来修改。别忘了GRU (LSTM)层只是计算隐藏状态的另一种方式,因此我们需要在前向转播的代码里,把隐藏层的计算步骤修改一下。

▲Tip:点击图片可看大图
我们也在实现中增加了偏置单元 b, c,这在之前的式子中没有体现。由于参数U和W的维度有所改变,还需修改参数U和W的初始值。Gitub上已有该初始化编码(https://github.com/dennybritz/rnn-tutorial-gru-lstm),在此就不一一展示。
在这里,我还添加了一个词嵌入层(word embedding)E,后文会有详细介绍。
接下来说说梯度。像之前一样,我们可以用链式求导法则推导E、W、U、b和c的梯度。但在实际操作中,多数人偏爱用像Theano这样的框架来实现。如果你还想要自己计算梯度,就需要实现不同模块的求导算法。
这里,我们利用Theano来计算梯度:

差不多就是这样。为得到优质结果,也可在实现中额外使用一些技巧:
1.用RMSProp(SGD的一种优化算法)更新参数
在第二部分教程中,我们用随机梯度下降(SGD)的基础版更新了参数。结果不尽人意。但如果将学习率设置得足够低,SGD确实能让你得到非常好的训练效果,只是实际操作时会耗费大量时间。
为了解决这个问题,SGD还有有许多变体,如(Nesterov) Momentum Method、AdaGrad、AdaDelta 和RMSProp等等。这篇文章中有详述的总结(http://cs231n.github.io/neural-networks-3/#update)。
这里,我们将使用RMSProp这个方法,其基本原理是根据先前的梯度之和来调整每个参数的学习率。直观上,出现频率越高的参数学习率越小(因为梯度总和更大),反之亦然。
RMSProp的实现非常简单。我们保留每个参数的缓存变量,并在梯度下降时更新以下参数以及缓存变量,如下(以W为例):
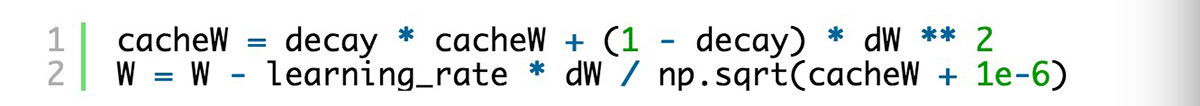
衰减通常设为0.9到0.95之间,另外,添加1e-6是为了避免除数为0。
诸如word2vec和GloVe这样的词嵌入( word embedding)是提升模型准确度的常用方法。和用one-hot表示句子不同,这种词嵌入的方法用低维(通常是几百维)的向量来表示词语,这有个好处,那就是能通过向量来判断两个词的语义是否相近,因为如果他们意思相近的话,他们的向量就很相近。要使用这些向量,需要预训练语料库。从直觉上来看,使用word embedding层,就相当于你告诉神经网络词语的意思,从而神经网络就不需要学习关于这些词语的知识了。
我的实验中并未使用预训练的单词向量,只添加了一个嵌入层(即编码中的矩阵E),便于插入单词。嵌入式矩阵与查表类似,第i栏的向量对应单词表中第i个词。通过更新矩阵E可自学单词向量,但仅针对我们的任务(以及数据集),不同于那些由大量文档训练而成的可下载的数据。
添加第二层能使网络捕捉到更高层次的交互,还可以添加其他层,但本实验中我没这么做。2到3层之后,可能会出现递减倒退(计算值逐渐减小),除非数据足够庞大(但我们没有),否则层数的增加不仅不会产生明显变化,还将导致过拟合。
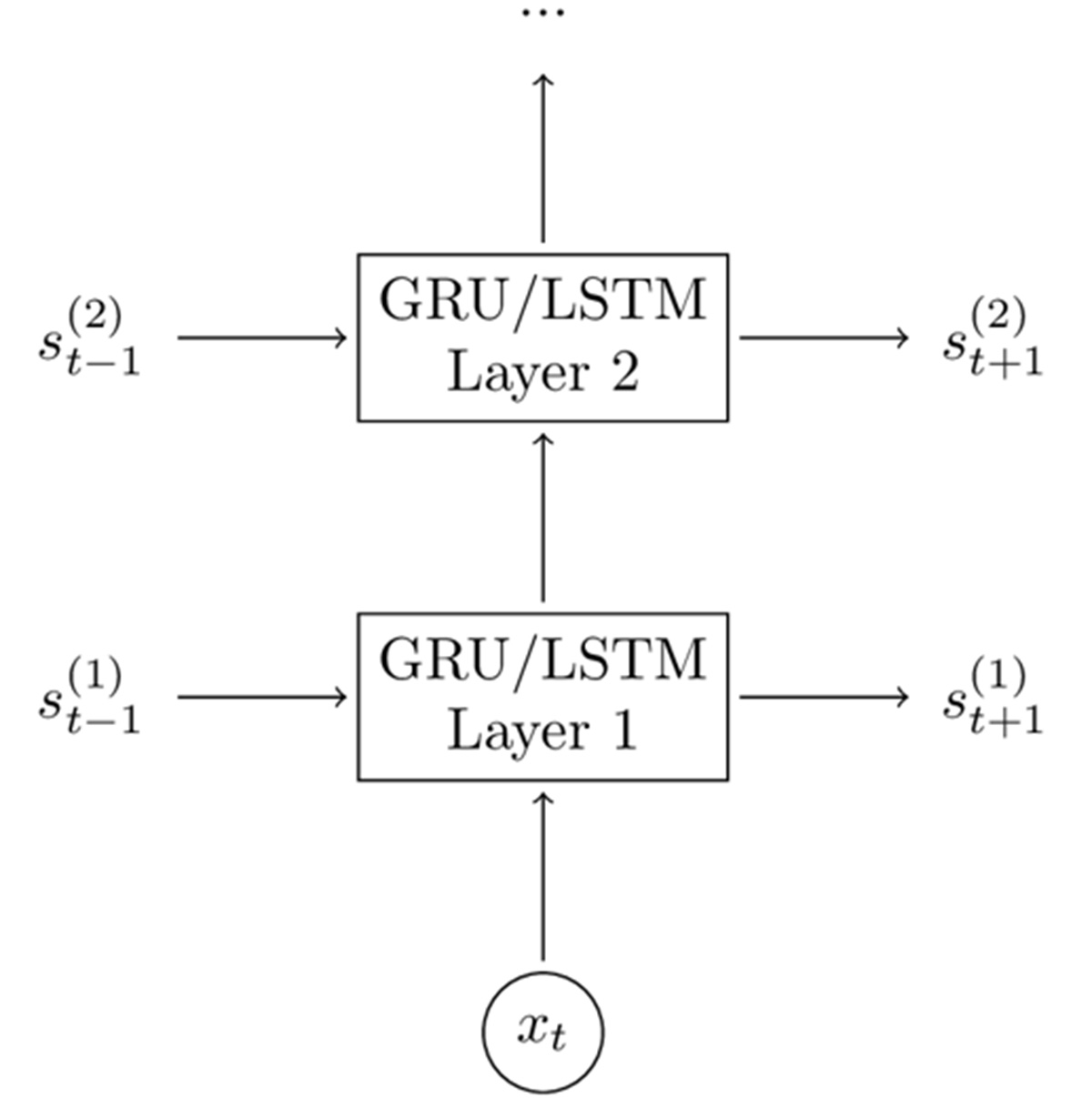
▲增加一层GRU或者LSTM
第二层的添加过程非常简单,只需(再次)修正前向传播的计算过程和初始化函数即可:

▲Tip:点击图片可看大图
此处附上GRU网络的完整代码:https://github.com/dennybritz/rnn-tutorial-gru-lstm/blob/master/gru_theano.py
之前我对此也有疑惑,因此提前声明,在此提供的编码效率较低,其优化版仅用于解说和教学目的。尽管它能够配合模型运作,但无法胜任生产或大型数据集训练。
优化RNN性能的方法有很多,但最重要的是批量处理所有更新。由于GPU能够高效处理大型矩阵乘法,因此你可以对相同长度的句子进行分组或将所有句子调整成相同长度(而非逐句学习),进行大型矩阵乘法运算并对整批数据梯度求和。不这么做的话,我们只能依靠GPU得到小幅提速,训练过程将会极其缓慢。
所以如果想训练大型模型,我首推那些经过性能优化的已有深度学习框架。训练一个模型,利用上述编码可能花费数日或数周,但借助这些框架只需要几个小时。我个人偏爱Keras,因其操作简单且附有许多RNN的示例。
5.结果
为节省训练模型的时间,我训练了一个与第二部分中类似的模型。该模型词汇规模为8000,我将词映射到48维向量并使用了两个128维GRU层。iPython notebook内含载入该模型的代码,可以操作或修改代码、生成文本。
以下为该网络输出的成功示例(我修改了大小写)。
多个时间步长后,观察句子的语义依赖性非常有趣。举个例子,机器人和自动化联系紧密,就像括号的两端。我们的网络能够学会这些,确实非常有用。
至此,本系列关于RNN的教程就结束,如果您对其它教程感兴趣,欢迎在评论区留言。科技行者将不遗余力为您呈上!

如果您非常迫切的想了解IT领域最新产品与技术信息,那么订阅至顶网技术邮件将是您的最佳途径之一。