

ɨһɨ
�������µ���
ɨһɨ
��ע�ٷ����ں�
����ͷ��
������ν“���������”�Ѿ���������ѧ�����������Ȼ���Խ��н�̸����ʻ���������������Ϸ����ȡΧ�����ھ������������ξ����������ƶ���ѧ���֣�����ͬʱ����������Ǵ����µ���ս——��Ϊ�о���Ա��δ�뵽���ѧϰ�����ܹ�ӵ����˳�ɫ������Ч�������˴�������Լܹ��еó���ģ�����֮�⣬ʱ�����գ������Բ���������������Ļ���ԭ��ָ������Щѧϰϵͳ��ʵ����ƣ�Ҳû���ܹ���������������ԭ������
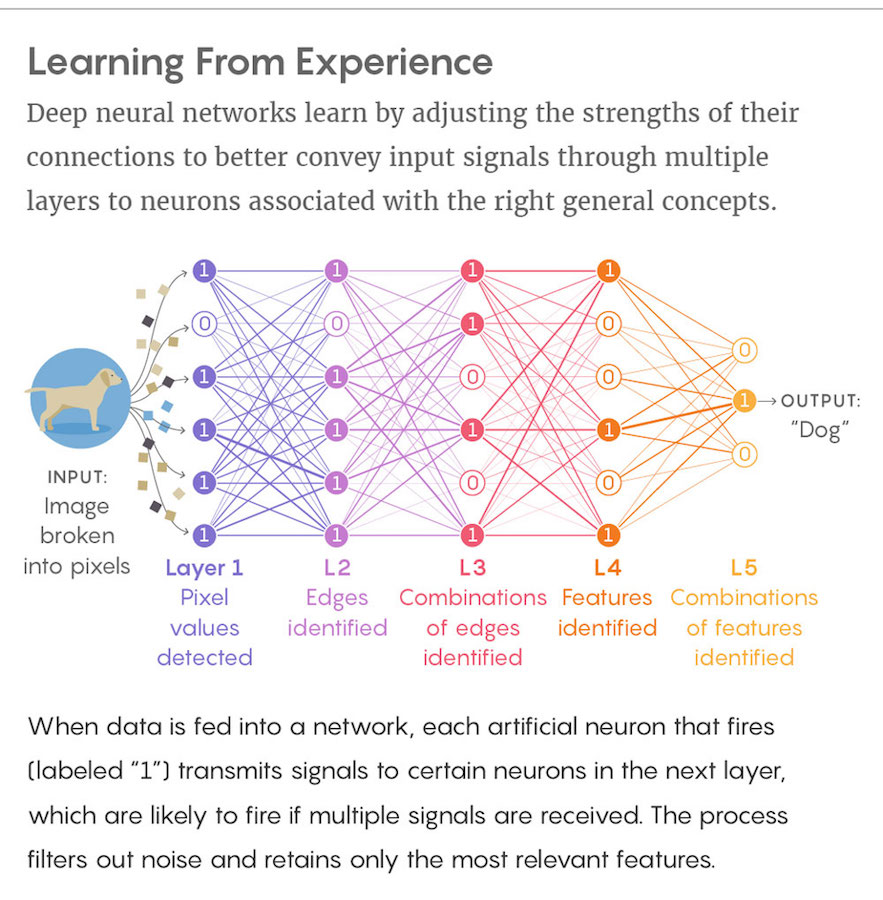
�����һ�������������ӵ�д�����Ԫ——�˹���Ԫ���Ǽ�����������������ijһ��Ԫ������ʱ����Ὣ�źŷ������ϲ���֮���ӵ���һ��Ԫ���������ѧϰ�����У������е����ӻ������Ҫ���м�ǿ��������Ӷ�ʹ��ϵͳ�ܹ����õط��������������ݣ�����һ��С��ͼƬ�еĸ����أ����źţ������ɸ�������ͨ����Ԫ�����ݹ�������ȷ�ĸ����——����“��”�������������Գ�ǧ������С��ͼƬ��������“ѧϰ”֮���伴��������һ��ȷ����ͼƬ�з��ֹ���һ������ѧϰ�����У����������������һ���Ը�����漣����֪�������������������������ڣ�����ζ����������������һ��ƾ�����������������Լ�������ͳ��Ϊ“����”���������Խ��ʵ�����⡣ר�������ں���֪�����ѧϰ������ʲô�����������Ƿ�����ͬ���ķ�ʽ������ʵ���
�ϸ��£��ڰ��־ٰ��һ��YouTube��Ƶ����Ҳ���ܹ�Ϊ�˹������о���Ա����DZ�ڵĴ𰸡��������У�Ү·����ϣ������ѧ�������ѧ�Ҽ���ѧ��Naftali Tishby�����֤����֧��һ���µ����ۣ�ϣ���ܹ���˶����ѧϰ�Ĺ���ԭ���������͡�Tishby��Ϊ������������Ǹ���һ����ν“��Ϣƿ��”������������ѧϰ�ģ���������1999���������λ���������ô����������״���������һ������뷨���ڣ��������������������ų���ϸ���������Ϣ�������ڼ�ѹ��Ϣ��ͨ��ƿ�������ս�������һ���Ը����������ǿ��������Tishby������ѧ��Ravid Shwart-Ziv��Ƴ��µļ����ʵ�飬ϣ������������ʵ�黷��չʾ��һ��ѹ���̾�������������ѧϰ���̵���ʵ�ֵġ�

Ү·����ϣ������ѧ�������ѧ�Ҽ���ѧ��Naftali Tishby
Tishby�ķ��ֺܿ����˹�������������䶯���ȸ蹫˾��Alex ALemi��ʾ��“����Ϊ��Ϣƿ����һ������δ��������������о��п��ܽ����ݷdz���Ҫ�Ľ�ɫ��”�������������µĽ��Ʒ�����ּ�ڶԴ�����������������Ϣƿ��������Alemi���ͳƣ�“��һƿ�������ܹ���Ϊ����������ʵ�ʹ���ԭ���������Թ��ߣ�ͬʱҲ����Ϊ��������������ܹ��ĸ���������”
һ�����о���Ա��Ȼ���ɸ����۾����Ƿ��ܹ��������ѧϰ����õijɹ������������û���ѧϰ���������������Ӷ�ײ����������ײ״̬��ŦԼ��ѧ��������ѧ��Kyle Cranmer��Ϊ��������ѧϰ��һ����ԭ��Ƕ���������һ����“������ͦ�е���”��
ͬʱ�ڹȸ蹫˾������ѧ��ְ�����ѧϰ��������Geoffrey Hinton�ڹۿ��˴˴ΰ����ݽ�֮����Tishby����һ������ʼ�����д��“��dz���Ȥ���ұ�������һ����������������е����ݡ���������������������������ԭ���Ե�˼ά����ܿ��ܴ�����һ���ش�����ӭ������ȷ��——��ϲ�ɺأ�”
����Tishby�Ĺ۵㣬��Ϣƿ��Ϊ����ѧϰ�����һ�����ԭ��——�����Ƕ����㷨�������ֻ����κ���������ʶ�Ĵ��ڣ����������Խ�����Ϊ���������㣬���dz������������εĴ�Ӧ����“ѧϰ��������Ҫ�IJ�����ʵ��������”��
Tishby���Ͷ������Ϣƿ���о�����ʱ�������о���Ա�Ÿոտ�ʼ�������������——������ʱ����������û�б���ʽ��������ʱ���������Ͱ�ʮ�����Tishby���ڿ�������������ʶ�����ʵ�ʱ���——��Ե�ʱ���˹����ܻ���һ������ս��Tishby��ʶ�����������ĺ������������——�����ʻ����������ߵ�����������ʲô��������δ���֮��صı���������ijЩ���������������������Լ������һ���������������ʵ�����е����ݺ���ʱ������Ӧѡ������Щ�źţ�
Tishby���ϸ��½��ܲɷ�ʱ��ʾ��“��������Ϣ��صĸ���������ʷ�ϱ�����ἰ��������û�ܵõ���ȷ�ı�������������������һֱ��Ϊ��Ϣ���۲����ǽ������Ե���ȷ;������ֻ��Shannon���˳�������һ����Ը���뷨��”
��Ϣ����ĵ�����Claude Shannon��ij�������Ͻ������Ϣ�о�����������������������ʮ�����ʼ����Ϣ���ۿ�ʼ����Ϣ��Ϊ���������——��������ѧ�����ϵ�0��1��Shannon��Ϊ��“��Ϣ��������”������Tishby�Դ˱���ͬ������������Ϣ���ۣ�����ʶ��“���ǿ��Ծ�ȷ�ض�‘�����’�������塣”
������������X��һ���ӵ����ݼ�������С��ͼƬ�е�ȫ�����أ���Y����һ���ܹ�������Щ���ݵļ��������絥��“��”�����ǿ��Ծ����ܵ�ѹ��X��ͬʱ��֤��ʧȥԤ��Y������������������X�в���ȫ��“�����”��Ϣ����1999�귢�������ĵ��У�Tishby����������Fernando Pereira����Ч���ڹȸ蹫˾���Լ�William Bialek������ְ������˹�ٴ�ѧ����������Ϊһ����ѧ�Ż����⡣�����ԣ���ֻ��һ��������˼�룬��֧����������ʵӦ�á�
Tishbyָ����“���Ѿ��ڸ��ֱ���֮�¶��������˼������ʮ�ꡣ���˵��ǣ������������翪ʼ��������Ҫ��”
��Ȼ���������Ļ�������������ʮ��ǰ���Ѿ�������������ѵ���������Ľ�������������������ǿ������������ͼ��ʶ������ı���ֱ��2010���ո¶ͷ�ǡ�Tishby���Ķ�������ѧ��David Schwab��Pankaj Mehta��2014�귢����һƪ���˾��ȵ�����֮��������ʶ��������Ϣƿ��ԭ��֮�������DZ����ϵ��
��λ���߷��֣�Hinton����������ν“�����������”��һ���ѧϰ�㷨�ܹ����ض�����£��ر�������������Ӧ��������ϵͳ����ͨ����ϸ�ڽ��д�����ת�����Ŵ�����ϵͳ���Ӷ�����������״̬����Schwab��Mehta�������������Ӧ�õ�����ģ�͵�“�ٽ��”������ʱ��ϵͳ�ڸ��������߶�֮�ϽԴ��ڷ����Ի�����������������������Զ������������������Ĺ�����ʶ��ģ��״̬��������������ѧ��Ilya Nemenman��ʱ���ԣ�����һ�־��˵ļ���“��ͳ��������һ����֮����ȡ����������������ѧϰ��������ȡ��������Ѿ���Ϊͬһ�������”
����Ψһ���������ڣ�һ��������ʵ�����еķ����Խ�Ϊ������Cranmer��ʾ��“��Ȼ����������ֳ��������ص�����״̬������������Ϊ�������ˡ������۾������IJ��컯�Ų������������������������������ѧϰ��������Ȼͼ��ʶ����������õ�ԭ��”������ʱ���ڽ������ٰ��������Ƶ�Tishby��ʶ�������ѧϰ�������ת������Ӧ�ɱ������Ϊ�㷺��˼·���С���ָ����“˼����ѧ�Լ�˼���Ҿ���˼ά�����ã��ǰ�����ʵ�ֿ�������Ҫ֧����”
2015�꣬��������ѧ��Noga Zaslavsky�����ѧϰ����Ϊһ����Ϣƿ�����̣���ᾡ���ܵ�ѹ���������ݣ�ͬʱ�����������ݵĴ�������Ϣ��Tishby��Schwartz-Ziv������������罨������ʵ�飬��ʾ��ƿ���������ʵ�ʷ������á�������һ�������У��о���Ա���ÿ�ѵ����С������ͨ��1��0�������й�����������������ݣ�������282�������������ʼ���ơ��ڴ�֮�����ǿ�ʼ���������ѧϰ�����������һ�װ���3000���������������ݼ�����ѵ����

 Noga Zaslavsky����Schwartz-Ziv���ң�
Noga Zaslavsky����Schwartz-Ziv���ң�
�ڴ�������ѧϰ�����У����ڵ�������������Ӧ�������ݵĻ����㷨����Ϊ“����ݶ��½�”��ÿ��ѵ�����ݱ����������統��ʱ������һ�����������Ͼ������˹���Ԫ�㡣���źŵ��ﶥ��ʱ�����յļ���ģʽ���ܹ���ͼ�����ȷ��ǩ���бȽ�——��1��0���й����������ּ���ģʽ����ȷģʽ֮����κβ��춼������“����”��ʽ�������²㣬����ζ����������ʦ�����Ծ�һ�������㷨�ܹ���ǿ�����ÿ�����ӣ�ʹ��������ܹ����õز�����ȷ������źš���ѵ������� ��ѵ�������еij���ģʽ����ӳ�����ӵ�ǿ��֮�ϣ������籾��Ҳ��ͨ��ѵ���������ݱ�ǵ���ȷ��——����ʶ��С�������ʻ���1��
��ʵ�鵱�У�Tishby��Shwartz-Ziv���������������ÿһ�������������Ϣ�����Լ��������������ж�����Ϣ�õ���������ѧ���Ƿ��֣���������������Ϣƿ�����۽���������Tishby��Pereira��Bialek��ԭʼ�������趨��һ���������ޣ��������ϵͳ�ܹ��ڽ����������Ϣ��ȡʱ��õ���ѽ��������һ�ٽ���ϣ��������ܹ�������ѹ���������ݣ�ͬʱ����Ӱ�쵽������ȷԤ���������
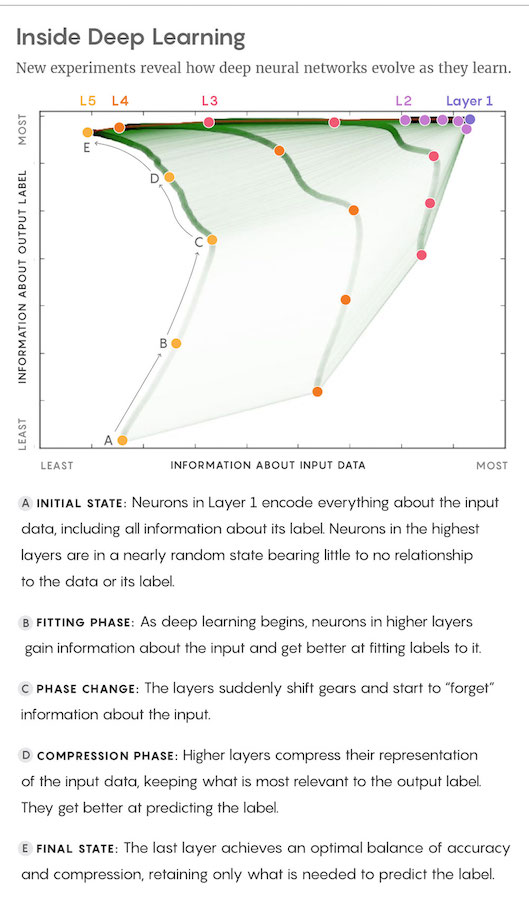
�Σ�һ����̵�“���”�Σ��ڴ˽��У�������ѧϰ����ѵ�����ݽ��б��; ������Ϊ������ѹ���Σ��ڴ˽������ø�ǿ��ķ�������������������ʵ�������ڶ��²������ݵı��Ч���ϡ�
�����������ͨ������ݶ��½�������������ʱ��������洢�Ĺ����������ݵı������ֻᱣ�ִ��º㶨�������ӣ����ͬʱ���ӵ����Զ������е�ģ�ͽ��б��룬�����籾��Ҳ�����õ�����ȷ��ǩ�����ϡ�����ר�ҽ���һ�α���Ϊ����ļ�����̡�
������ѧϰ�����л���ѹ���Ρ������翪ʼ���������������йص���Ϣ������������ǿ�������——�����������ǩ�������ߵ�������֮���Իᷢ���������������Ϊ����ݶ��½���ÿһ�ε������У�ѵ�������ж������ٴ������������Ը�֪������������ͬ���жϣ��⽫����������²�����Ե��������ӵ�ǿ�ȡ������������ѹ��ϵͳ�������ݵı���Ч����ȫһ�¡�������˵��ijЩС����Ƭ�п��ܴ��ڱ������ݣ���ijЩ����������һ��������ѭ��������Щѵ����Ƭʱ�����ܻ�“����”ijЩ��Ƭ�з����빷֮�������ԣ�������Ϊ������Ƭ�еIJ�����Ի�������ֹ�����Tishby��Shwartz-Ziv��Ϊ���������ֶ�ϸ����Ϣ����������ʹϵͳ�γ�һ���Ը����ʵ�ϣ����ǵ�ʵ���������������������ѹ��������˷����������Ӷ��������ڲ������ݱ�Ƿ���ij�Ч��һ����ѵ����С��ͼ��ʶ����������罫�ܹ���������Ƭ���в��ԣ���ȷ�ж������Ƿ��������һ����
��Ϣƿ�������Ƿ��������������ѧϰ���ƣ��Լ���ѹ��֮���������Щ��������;����Ŀǰ���д��۲졣һ�����˹�����ר����Ϊ��Tishby�������ǽ��ڳ��ֵ������ѧϰ��ص��ڶ༫Ϊ��Ҫ��ָ����ԭ��֮һ�������ѧAI�о�Ա��������ѧ��Andrew Saxeָ����ijЩ��ģ�dz��Ӵ������������ƺ�������Ҫ����������ѹ���Ρ��෴���о���Ա������ν“����ֹͣ”�������б�̣������ܹ���Ч����ѵ��ʱ�䲢��ֹ��������д��ڹ�������ԡ�
Tishby��Ϊ��Saxe������ͬ��������������ģ�Ͳ�ͬ�ڱ����������ܹ�������������Σ���Ϣƿ����������۽������˴�������ķ���Ч��Ҫ�������������á�Tishby��Shwartz-Ziv������ʵ����һ���̶��Ͻ�����ƿ���Ƿ������ڽϴ��ģ�����ߵ����⡣������ؽ��δ������ԭʼ���ĵ��У�����������Щʵ����ѵ���˹�ģ��Ϊ�ɹ۵İ���33������ӵ���������磬����ʶ�����Թ��ұ��뼼���о�Ժ��6�����д����ͼ��——�������ݼ����Ǻ������ѧϰ�㷨���ܵ��������زġ���ѧ���Ƿ��֣��������ʵ�ʱ�������Ϣƿ�������۽�������ͬ��; ���ǻ�������С��������ȣ����״��ģ���ѧϰ����������θ���������Tishbyָ����“��������ȫ������Ϣƿ������һ���ձ�����”
���������
��������δ����ǵĸйٵ���ɸѡ�źŵģ�����ν������������Ծ�����ʶˮƽ���У���һ���ؿ����ƶ����˹������������о�����������������Ȥ����������ʽ��Ƴ����Ե�ѧϰ�����˹����ܴ�ҵ���ںܴ�̶����Ѿ���������������֮·��ת����ʼ��������;��С������Ч�ܱ��֡�������ˣ��������ܻ�����ȡ�õijɾ���������——������ijЩ�˿�ʼ�����˹���������һ�콫����������в�������о���Աϣ������̽���ܹ���ʾ�����ڻ���ѧϰ������ʵ�ֵ�һ���Խ��ۡ�
ŦԼ��ѧ����ѧ�����������ܶ���������Brenden Lake���о����������ѧϰ�����ͬʱ��ʾ��Tishby�ķ��ִ�����“���������ϻ����Ҫһ��”������ͬʱǿ�����Դ�����һ�������ڵĺ�ϻ�ӡ����dz����˵Ĵ���ӵ��860�ڸ���Ԫ����˴˼�����Ӹ��Ƕ����������������һ�п��ܶ���Ҫƾ��ijЩ��������ǿ�����������Ӷ�ʵ�ֳ�ԽӤ���ڵĻ���ͼ��������ʶ��ѧϰ���̡����ⷽ�棬��ܿ�����Ŀǰ�����ѧϰ�����൱���ơ�
������˵��Lake��ΪTishby�����ֵ������ѹ�����ƺ����ͯ����д��ĸѧϰ���̲������ơ������Dz�����Ҫ�۲��ǧ�������ĸ�����úܳ�ʱ������������ѹ��; �෴�������ܹ�����ʶ���ͬһ��ĸ������ʵ����ѧϰ�����д��ʵ���ϣ����������ܹ����õ�һ���ӽ���ѧϰ��Lake����ͬ���ǵ�ģ�ͱ����������ܹ�������ĸ���һϵ�бʻ�——������ �Ѿ����ڵ������ṹ���Ӷ�����ԭ����֪������ĸ���Lake���ͳƣ�“�Ҳ�����ż��ϵ�ͼ�������һ�������أ����������ѧϰ�㷨��������Щ��������ӳ�䡣�ҵ�Ŀ�����ڽ���һ��Ϊ�����ģ�ͣ�”��ʵ��һ�����̵ķ���·����
����������ʵ�ַ�ʽ���ܻ��AI��ҵ����ָ��������ʹ��������ʵ���������Tishby��Ϊ����������ѧϰ���˹�����ѧϰ��Ϊ�ձ飬��������Ϣƿ���������ս�������ѧ�Ƶ��з������á������۲�����Եó���ֱ�Ӽ��⣬�ܹ��������Ǹ��õ�������Щ���������ܹ�Ϊ������ҵ���������Щ��Ҫ�˹����롣Tishby��ʾ��“����ڿ�ѧϰ��������������������������Щ������‘�ҿ����������������еĸ�����Ϣ������������’�����⡣��һ����������Ȼ�Ӿ�������ʶ���У�Ҳͬ���������ǵĴ����ܹ������ʵ������”
���ͬʱ����ʵ���˹�������Ҳ��������ͬ������ս����ÿ�������ϸ�����������Ӱ�����վ[��������˵���������������������������ֵ���Ӽ��㡣Tishbyָ����“�������ⳤ�����������ǣ���ʵ��������������ܵ�ijһ������Ӱ�졣���ࡢ��ɢ�����������������ˡ�����Ϊ���ѧϰ���������ƽ����롣”
����——������Ϣƿ�����б�������ζ�Ŷ�������ϸ����Ϣ�������ʵʱ�������㲻̫�Ѻã�������������Ȼ���Ǵ��Ե���Ҫ�����ԵĹ������ڰ������Ǵ���Ⱥ��Ѱ����Ϥ����ס���ʶ�����е������������������е����������źš�
��Դ��QuantamaGazine
���ߣ�Natalie Wolchover
�����������Ƽ�����

������dz����е����˽�IT�������²�Ʒ�뼼����Ϣ����ô���������������ʼ������������;��֮һ��