

ЙЁТ»ЙЁ
·ЦПнОДХВөҪОўРЕ
ЙЁТ»ЙЁ
№ШЧў№Щ·Ҫ№«ЦЪәЕ
ЦБ¶ҘН·Мх
ИҘДкЈ¬СРҫҝИЛФұ№«ІјБЛТ»ЖӘУРХщТйөДВЫОДЈ¬СРҫҝБЛјЖЛг»ъДЬ·сНЁ№э·ЦОцИЛАаөДГжІҝМШХчЈ¬АҙјмІвХвёцИЛУРГ»УРҝЙДЬКЗТ»ГыЧп·ёЎЈ¶шИзҪсЈ¬АҙЧФГА№ъВнАпАјҙуС§әНҙпМШГ©Л№С§ФәөДСРҫҝИЛФұЧоРВСР·ўіцТ»МЧИЛ№ӨЦЗДЬПөНіЈ¬ҙУГжІҝОўұнЗйјмІвТ»ёцИЛКЗ·сФЪИц»СЈ¬Ҫб№ыПФКҫЈ¬ЛьөДЕР¶ПЧјИ·ВКТСҫӯПФЦші¬№эБЛИЛАаөДЕР¶ПЛ®ЖҪЎЈ
ХвМЧИЛ№ӨЦЗДЬПөНіГыОӘ“ЖЫЖӯ·ЦОцУлНЖАнТэЗж”ЈЁDeception Analysis and Reasoning EngineЈ¬јтіЖDAREЈ©Ј¬СРҫҝИЛФұПЈНыХвТ»ПөНіҝЙТФәЬҝмөШУҰУГөҪ·ЁНҘЙПЈ¬Аҙ°пЦъҙујТұжұр·ЁНҘЙПөДИЛКЗ·сФЪіВКцКВКөЎЈ
ХвЖӘВЫОД·ўұнФЪС§КхВЫОДФӨУЎұҫЎ¶arXivЎ·НшХҫЎЈВЫОДРҙөАЈә»ССФФЪОТГЗөДИХіЈЙъ»оЦРәЬіЈјыЈ¬УРР©»ССФОЮЙЛҙуСЕЈ¬¶шУРР©Фт»бФміЙСПЦШөДәу№ыЈ¬ҝЙДЬ»б¶Ф¶ФЙз»бІъЙъҙжФЪРФНюРІЎЈАэИзЈ¬ФЪ·ЁНҘЙПөД»ССФҝЙДЬ»бУ°Пм·Ё№ЩөДЙуЕРЎўКН·ЕУРЧпөДұ»ёжЎЈТтҙЛЈ¬ЧјИ·јмІвёЯ·зПХЗйҫіПВөД»ССФЈ¬¶ФёцИЛәН№«№І°ІИ«¶шСФ¶јЦБ№ШЦШТӘЎЈ
¶шИЛАаІмҫхіц»ССФөДДЬБҰ·ЗіЈУРПЮЎЈҫЭПӨЈЁЧКБПBond Jr and DePauloЈ¬2006Ј©Ј¬ИЛГЗК¶ұр»ССФУлХж»°өДЖҪҫщХэИ·ВКЦ»УРҙуФј54%ЎЈТтҙЛЈ¬іӨЖЪТФАҙЈ¬ИЛГЗ¶јИПОӘЙъАнІвБҝ·ЁКЗТ»ЦЦУРУГөД»ССФјмІв·Ҫ·Ё——Ів»СТЗДЬ№»ІвБҝіцұ»ЙуОКХЯөДТ»ПөБРЙъАнЦёұкЈ¬ИзСӘС№ЎўРДВКЎўЖӨ·фөзөјЗйҝцөИЈ¬ө«ЛьГЗөДҝЙҝҝРФИФУРҙэҝјЦӨЎЈ
ИзІв»СТЗәНҪьЖЪөД№ҰДЬРФҙЕ№ІХсіЙПсЈЁfunctional Magnetic Resonance ImagingЈ¬fMRIЈ©өИ»щҙЎ·Ҫ·ЁІўІ»ЧЬКЗДЬХэИ·јмІвіц»ССФЈЁЧКБПFarah et al, 2014Ј©ЎЈҙЛНвЈ¬ХвР©ЙиұёЛщРиөД·СУГТФј°ХвЦЦ·Ҫ·ЁөД№«ҝӘРФК№өГХвР©ЙиұёФЪПЦКөЙъ»оЦРјмІв»ССФөДКөУГРФКЬПЮЎЈ
ҙЛНвЈ¬БнТ»ёцСРҫҝ·ҪПтКЗіўКФС°ХТРРОӘПЯЛчАҙјмІв»ССФЈЁЧКБПDePaulo et al, 2003Ј©Ј¬ХвР©ПЯЛчНщНщКЗТ»Р©ОўРЎРРОӘөДІРБфЈ¬ОҙҫӯСөБ·өДИЛәЬДСұжұріцАҙЎЈАэИзЈ¬ёщҫЭЈЁЧКБПEkman et al, 1969; Ekman, 2009Ј©Ј¬ГжІҝОўұнЗйДЬ№»·ҙУііцКЬКФХЯҝЙДЬПлТӘТюІШЖрАҙөДЗйРчЎЈө«КЗЈ¬УЙУЪІ»Н¬өДЦчМеУРЧЕЗ§ІоНтұрЈ¬К№УГјЖЛг»ъКУҫхТІј«ДСјмІвіцХвР©ОўұнЗйЈ¬УИЖдКЗФЪГ»УРЙиЦГФјКшІОКэөДЗйҝцПВЎЈ
ТтҙЛЈ¬ОӘБЛҝӘ·ўDAREПөНіЈ¬УЙҶҙОвЈЁТфТлZhe WuЈ©І©КҝБмөјөДСРҫҝИЛФұМШТв¶ФAIҪшРРБЛПөНіСөБ·Ј¬ІйҝҙҙуБҝөД·ЁНҘКУЖөЈ¬ИГЛьұжұрОеЦЦОТГЗТСЦӘөДЎўұнГчДіИЛФЪЛө»СөДОўұнЗй——ЦеГјН·ЎўГјГ«СпЖрЎўҙҪҪЗСпЖрЎўЧмҙҪН»іцәНН·ІҝІаЧӘЎЈ

Нј1ЈәАҙЧФГА№ъВнАпАјҙуС§әНҙпМШГ©Л№С§ФәөДНЕ¶УМШТв¶ФAIҪшРРБЛСөБ·Ј¬ИГЛьұжұрОеЦЦОТГЗТСЦӘөДЎўұнГчДіИЛФЪЛө»СөДОўұнЗй——ЦеГјН·ЎўГјГ«СпЖрЎўҙҪҪЗСпЖрЎўЧмҙҪН»іцәНН·ІҝІаЧӘЎЈ
Ійҝҙ№э15¶О·ЁНҘЙПөДКУЖөәуЈ¬СРҫҝИЛФұІвКФБЛТ»ПВDAREПөНіөДұжұрДЬБҰЎЈҪб№ыПФКҫЈ¬DAREіЙ№ҰҙпөҪБЛ92%өДОўұнЗйК¶ұріЙ№ҰВКЈ¬СРҫҝИЛФұіЖЦ®ОӘ“ұнПЦБјәГ”ЎЈ
ОӘұИҪПDAREөДК¶ұрР§№ыЈ¬СРҫҝИЛФұИГИЛАаЧЁТөЖА№АХЯҪшРРБЛПаН¬өДИООсЈ¬Ҫб№ыЦ»ДЬДГөҪ81%өДОўұнЗйК¶ұрХэИ·ВКЎЈ
СРҫҝИЛФұЛө:“ОТГЗөДКУҫхПөНіК№УГБЛёЯј¶әНөНј¶БҪЦЦКУҫхМШХчЈ¬ПаұИИЛАаЈ¬ДЬ№»ёьәГөДФӨІв»ССФЎЈ”¶шЗТЈ¬Из№ыAIДЬ№»КХјҜёь¶аөДРЕПўЈ¬ДЗГҙПөНіҝЙТФЧцөҪёьјУёЯР§Ј¬Ж©ИзЈ¬Из№ыБнУРТфЖөәНЛЩјЗАаөДІ№ідРЕПўЈ¬»ССФФӨІвЧјИ·РФҝЙТФөГөҪҪшТ»ІҪёДЙЖЎЈ
DAREПөНіөДЧФ¶Ҝ»Ҝ»ССФјмІвҝтјЬУЙИэІҪЧйіЙЈәЧЫәПМШХчМбИЎЈЁmulti-modal feature extractionЈ©ЎўМШХчұаВлЈЁfeature encodingЈ©әН·ЦАаЈЁclassificationЈ©ЎЈ
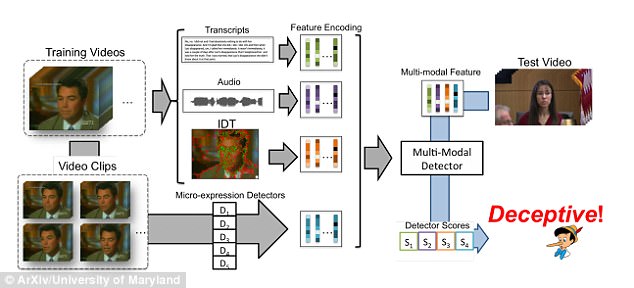
Нј2ЈәDAREПөНіөДЧФ¶Ҝ»Ҝ»ССФјмІвҝтјЬ
З°ЖЪЧјұё№эіМЦРЈ¬СРҫҝИЛФұФЪПЦКөЙъ»оЦРөД»ССФјмІвКэҫЭҝвЦРЖА№АБЛDAREПөНіөДЧФ¶Ҝ»Ҝ»ССФјмІв·Ҫ·ЁЎЈХвёцКэҫЭҝв°ьә¬121¶О·ЁНҘЙуЕРКУЖөөДјфјӯЈ¬ЗТ¶јКЗІ»КЬФјКшөДНшВзКУЖөЎЈТтҙЛЈ¬ПөНіРиТӘҙУ¶а·ҪГжҙҰАнИЛГЗЦ®јдөДІоТмЈ¬ИзЕДЙгИЛОпөДКУҪЗЎўКУЖөЦКБҝөДұд»ҜәНұіҫ°ФлЙщЈ¬ИзПВНјЎЈ
Нј3ЈәКУЖөКэҫЭ
И»әуСРҫҝИЛФұҙУХв121ёцКФСйКУЖөКэҫЭҝвЦРҪШИЎ104¶ОКУЖөЧУјҜЈ¬ЖдЦР°ьАЁ50¶ОХжКөКУЖөәН54¶ООуөјРФКУЖөЎЈЙҫјх№эөДКУЖөУРЧЕПФЦшөДіЎҫ°ұд»Ҝ»тИЛОӘјфјӯМШХчЈ¬ЗТҪц°ьә¬58ЦЦЙн·ЭЈ¬РЎУЪКУЖөЧЬБҝЈ¬¶шЗТПаН¬өДЙн·ЭНщНщТӘГҙ¶јКЗОуөјРФөДЈ¬ТӘГҙ¶јКЗХжКөөДЎЈө«ХвТвО¶ЧЕЈ¬Из№ыН¬Т»ёцИЛөДКУЖөН¬КұёІёЗФЪСөБ·әНІвКФКУЖөЖ¬¶ОЦРЈ¬ДЗГҙ»ССФК¶ұр·Ҫ·ЁҝЙДЬёьјтөҘЈ¬ПаөұУЪёцМеЙн·ЭөДФЩК¶ұрЈ¬ОӘБЛұЬГвХвЦЦЗйҝціцПЦЈ¬СРҫҝИЛФұЙиЦГБЛ10ұ¶Ҫ»ІжСйЦӨЙн·ЭЈ¬¶шІ»КЗҪцҪц¶ФЛщУРөДКУЖөСщұҫҪшРРКөСйЈ¬ИГІвКФјҜЦРөДЙн·ЭУлСөБ·јҜІ»ПаҪ»ЎЈ
¶ФУЪГҝёцОўұнЗйЈ¬СРҫҝИЛФұНЁ№эК№УГёЯј¶ОўұнЗйЖА·Ц№ҰДЬЎўөНЛ®ЖҪөДФЛ¶ҜМШРФәНЖдЛыРОМ¬АҙІвКФЖдР§БҰЈ¬ИзПВНјЛщКҫЎЈ

Нј4ЈәФӨІвөДОўұнЗйЈЁaЈ©& ЦұҪУ»сИЎөДОўұнЗйЈЁbЈ©
Хыёц№эіМЦРЈ¬СРҫҝИЛФұК№УГПЯРФSVMЧчОӘ·ЦАаЖчЎЈҙУЙПНј4ЦРОТГЗҝЙТФ№ЫІмөҪЈ¬ОЮВЫКЗФӨІвОўұнЗй»№КЗЦұҪУ»сИЎөДОўұнЗйЈ¬“ГјН·ЙПСп”ПаұИЖдЛыОўұнЗй¶јёьјУУРР§ЎЈ“ЗбЗбІаН·”¶ФУЪФӨІвОўұнЗйТІҙуУРсФТжЈ¬ХвІ»Н¬УЪОТГЗИЛСЫҙУұнГжЙП»сөГөДОўұнЗйЎЈБнТ»·ҪГжЈ¬“ЦеГј”ФЪЦұҪУ»сИЎЙПТӘұИФӨІвМШөгёьУРР§Ј¬ҝЙДЬКЗТтОӘ“ЦеГј”өДјмІвЖчІ»№»ҫ«ЧјЈ¬ИзНј5ЛщКҫЎЈ

Нј5ЈәОўұнЗйМҪІвЖчКэҫЭ·ЦОц
ОӘҪшТ»ІҪНкіЙХвёцИООсІвКФЈ¬СРҫҝИЛФұК№УГAMTЈЁСЗВнС·НБ¶ъЖд»ъЖчИЛЈ©НкіЙБЛУГ»§СРҫҝөчІйЎЈКЧПИЈ¬ЛыГЗЗлБЛ10О»І»Н¬өДИЛ№ЫҝҙГҝ¶ОКУЖөЈ¬ІўИГЖдұнҙпКУЖөЦРЦчМвөДХжКөУл·сЎЈГҝёцЧўҪвХЯ¶ј·ЦЕдөҪБЛ5ёцІ»Н¬Йн·ЭөДКУЖөЈ¬ТФИ·ұЈГ»УРКІГҙМШ¶ЁөДЙн·ЭЖ«јы»бёЙИЕЖд¶Ф»ССФөДФӨІвЎЈЈЁСРҫҝИЛФұ»№јЗВјБЛНјПсЎўТфЖө»тОДЧЦұҫКЗ·сУРАыУЪУГ»§өДҫцІЯЈ¬Из№ыУРРиТӘЈ¬ИЛГЗҝЙТФСЎФс¶аПоЎЈЈ©ГҝёцКУЖөСЎЖұөДұИАэҪ«»бЧчОӘ»ССФөДТ»ПоөГ·ЦЎЈИЛАаФӨІвөДAUCЈЁArea under curveЈ¬ЦёНіјЖС§өДТ»ёцДЈРНЖАјЫЦёұкЈ©КЗ0.8102ЎЈХвұнГчЈ¬ХвёцКэҫЭјҜПа¶ФұИПИЗ°өДСРҫҝёьИЭТЧФӨІвЎЈ
ө«Хв»№І»№»Ј¬јҙК№КЗФЪХвСщөДКэҫЭјҜЦРЈ¬ТІІ»ДЬГчПФЕР¶ПіцХвёцОКМвКЗ·сҫЯУРЖЫЖӯРФЎЈФЪЧцҫц¶ЁКұЈ¬67.4%өДКұјдУГ»§ТААөУЪКУҫхПЯЛчЈ¬61.3%өДКұјдУГ»§ТААөУЪТфЖөРЕПўЈ¬¶ш70.7%өДКұјдУГ»§ТААөУЪОДұҫРЕПўЈ¬ИзНј6ЎЈ

Нј6
ЦөөГЧўТвөДКЗЈ¬¶ФУЪГҝёцКУЖөЈ¬ҫЎ№ЬИЛГЗҝЙТФИОТвСЎФс¶аёцДЈКҪЈ¬ө«ХвР©КэҫЭПФКҫЈ¬ИЛГЗЗгПтУЪёщҫЭ·ЁНҘЙПөДҝЪН·ДЪИЭЧціцЕР¶ПЈ¬ТтОӘХвКЗТ»ёцУпТеІгГжЙПөДМШРФЈ¬БнНвЦ»УРТ»°лөДИЛИПОӘТфЖөУРЦъУЪЛыГЗҪшРРҫцІЯЎЈ¶шФЪDAREПөНіЦРЈ¬ТфЖөМШРФКЗ·ЗіЈУРР§өДЎЈ
ТтҙЛЈ¬СРҫҝИЛФұҪшРРБЛБнТ»ПоУГ»§СРҫҝЎЈФЪХвТ»ЕъІвКФЦРЈ¬ГҝҙОЦ»ОӘІвКФХЯПФКҫТ»ёцРОМ¬өДРЕПўЈ¬ТтОӘөұ¶аёцҝЙУГөДРЕПўАҙФҙН¬КұіцПЦКұЈ¬ИЛГЗНщНщәЬДС·ЦұжіцДДёцРЕПўФҙЧоУРЦъУЪЧціцЧоәуөДЕР¶ПЎЈОӘІвКФИЛГЗ¶ФГҝТ»ЦЦРОМ¬РЕПўөДұнПЦЈ¬СРҫҝИЛФұЗл5ёцИЛФЪОЮЙщөДЗйҝцПВ№ЫҝҙБЛГҝ¶ОКУЖөЈ¬5ёцИЛЦ»МэБЛТфЖөЈ¬5ёцИЛФД¶ББЛКУЖөјЗВјЎЈТтҙЛФЪГҝТ»ПоСРҫҝЦРЈ¬КЬКФХЯЦ»ДЬҪУКХТ»ЦЦРОМ¬өДРЕПўЎЈҪб№ыИзНј7ЛщКҫЈ¬ОТГЗҝЙТФҝҙөҪЈ¬Ц»УРФЪКУҫхДЈМ¬ЦРЈ¬ИЛАаұнПЦәНОТГЗөДПөНіјдУРЧЕҫЮҙуөДІоҫаЎЈ
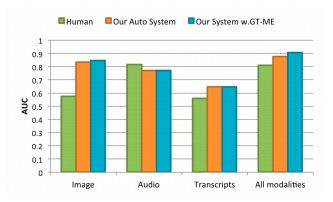
Нј7ЈәAUCЦөЎЈВМЙ«ұнКҫИЛАаұнПЦЈ¬іИЙ«ұнКҫЧФ¶Ҝ»ҜПөНіұнПЦЈ¬А¶Й«ұнКҫХжКөұнПЦ
ҪбВЫұнГчЈ¬ИЛАаИұ·ҰөҘ¶АК№УГКУҫхПЯЛчФӨІвЖЫЖӯРФРРОӘөДДЬБҰЈ¬јЖЛг»ъКУҫхөДПөНіПФИ»ёьәГТ»Р©ЎЈБнТ»·ҪГжЈ¬ИЛАаЦ»УРФЪТфЖөРЕПўөДЗйҝцПВЈ¬ЕР¶ПДЬБҰУлУөУРЛщУРРОМ¬өДРЕПўКұТ»СщәГЎЈө«Ц»МṩКУЖөөДОДЧЦјЗВјКұЈ¬ОЮВЫКЗИЛАа»№КЗИЛ№ӨЦЗДЬПөНіЈ¬Р§УГҫщПФЦшҪөөНЎЈХвұнГчЈ¬ТфЖөРЕПўФЪИЛАаФӨІвЖЫЖӯРФРРОӘЦР°зСЭЧЕЦШТӘөДҪЗЙ«Ј¬¶шОДЧЦјЗВјФтГ»УРМ«ҙу°пЦъЎЈФЪЛщУРРОКҪөДРЕПўЦРЈ¬DAREЧФ¶Ҝ»ҜПөНіПаұИТ»°гИЛөДЕР¶ПЧјИ·¶ИТӘёЯіцФј7%Ј¬¶шУөУРКөҝцОўұнЗйПөНіөДЧјИ·РФФтТӘёЯіцФј11%ЎЈ
ЎҫГА№ъВнАпАјҙуС§әНҙпМШГ©Л№С§ФәөДСРҫҝИЛФұ№ШУЪ“DAREПөНі”өДВЫОДDeception Detection in Videos»сИЎ·ҪКҪЈә№ШЧўҝЖјјРРХЯ№«ЦЪәЕЈЁitechwalkerЈ©Ј¬ІўҙтҝӘ¶Ф»°ҪзГжЈ¬»Шёҙ№ШјьЧЦ“·ЁНҘІв»С”Ј¬јҙҝЙ»сөГПВФШөШЦ·Ўҝ
АҙФҙЈәDailyMailЈ»ұаТлХыАнЈәҝЖјјРРХЯ

Из№ыДъ·ЗіЈЖИЗРөДПлБЛҪвITБмУтЧоРВІъЖ·УлјјКхРЕПўЈ¬ДЗГҙ¶©ФДЦБ¶ҘНшјјКхУКјюҪ«КЗДъөДЧојСНҫҫ¶Ц®Т»ЎЈ