

…®“Μ…®
Ζ÷œμΈΡ’¬ΒΫΈΔ–≈
…®“Μ…®
ΙΊΉΔΙΌΖΫΙΪ÷ΎΚ≈
÷ΝΕΞΆΖΧθ
ΉνΫϋΥΙΧΙΗΘ¥σ―ß“ΜΤΣ¬έΈΡΓΕDeep neural networks are more accurate than humans at detecting sexual orientation from facial imagesΓΖ“Μ≥ωΘ§”Ώ¬έΜ©»ΜΘ§ΗΟ¬έΈΡ―–ΨΩ÷Η≥ωΘ§ΦΤΥψΜζΥψΖ®Ω…“‘¥”Οφœύ≈–Εœ“ΜΗω»ΥΒΡ–‘»ΓœρΘ§“ΐΖΔΝΥΕ‘“ΰΥΫΓΔΒάΒ¬ΓΔ¬ΉάμΈ ΧβΒΡ’υ“ιΓΘ»ΜΕχΜΊΙΐΆΖ»ΞΩ¥Θ§’β‘≠±Ψ «“ΜΗωΨμΜΐ…ώΨ≠Άχ¬γ”Π”ΟΒΡΦΦ θΈΡ’¬Θ§‘Ύ»ΥΙΛ÷«ΡήΝλ”ρΘ§Υϋ «ΆΦœώ Ε±πΚΆΜζΤς»Υ ”ΨθΒΡΚΥ–Ρ≤ΩΖ÷ΓΘ
ΆΦœώ Ε±πΦΦ θΘ§ «»ΥΙΛ÷«ΡήΒά¬Ζ…œΒΡ“ΜΉυΗΏΖεΘ§»γΫώΡψΩ…“‘Ω¥ΒΫΑϋά®Ηω»Υœύ≤αΆΦΤ§ΙήάμΓΔΥΔΝ≥ΫβΥχ ÷ΜζΓΔΥΔΝ≥…œΑύ¥ρΩ®Β»ΙψΖΚ”Π”ΟΓΘΡψ“ΜΕ®ΚΟΤφΘ§ΆΦœώ Ε±π « ≤Ο¥ΘΩ»γΚΈ»ΟΜζΤςάμΫβ“Μ’≈ΆΦ…θ÷Ν“ΜΗωΕ·Χ§ΒΡ…ζΈοΘΩ±≥Κσ”÷”ΟΒΫΝΥΡΡ–©ΦΦ θΘΩ
ΫώΧλΘ§Έ“Ο«ΨΆ¥”‘¥ΆΖΆΎ“ΜΆΎΆΦœώ Ε±πΒΡΗ≈ΡνΓΔΦΦ θΚΆ”Π”ΟΓΘ
¥”Η≈Ρνά¥Ω¥Θ§ΆΦœώ Ε±π «÷Ηάϊ”ΟΦΤΥψΜζΕ‘ΆΦœώΫχ––¥ΠάμΓΔΖ÷ΈωΚΆάμΫβΘ§“‘ Ε±π≤ΜΆ§ΡΘ ΫΒΡΡΩ±ξΚΆΕ‘œώΘ®»ΥΈοΓΔ≥ΓΨΑΓΔΈΜ÷ΟΓΔΈοΧεΓΔΕ·ΉςΒ»Θ©ΒΡΦΦ θΓΘ
ΕχΆΦœώ Ε±πΥψΖ®“ΜΑψ≤…”ΟΜζΤς―ßœΑΖΫΖ®Θ§ΡΘΡβ»ΥΡ‘Ω¥ΆΦΘ§ΥφΚσΦΤΥψΜζ“άΩΩ¥σΝΩΒΡ ΐΨίΘ§άμΫβΆΦœώΘ§ΉνΚσΫ®ΝΔœύΙΊΒΡ±ξ«©ΚΆάύ±πΓΘ’ϊΗω Ε±πΙΐ≥ΧΒΡΚΥ–ΡΘ§ΨΆ «…ώΨ≠Άχ¬γΘ§Ψ≠Ιΐ”≈ ΛΝ”Χ≠Θ§ΡΩ«Α“―Ψ≠ΖΔ’ΙΒΫΨμΜΐ…ώΨ≠Άχ¬γΘ®CNNΜρConvNetsΘ©ΓΘ
Ψί≤ΜΆξ»ΪΆ≥ΦΤΘ§ΩΤ―ßΦ“Ο«¥”…ώΨ≠Άχ¬γ―–ΨΩΒΫΨμΜΐ…ώΨ≠Άχ¬γΘ§ΨΆΜ®ΝΥ¥”20 άΦΆ60Ρξ¥ζΡ©ΒΫ20 άΦΆ80Ρξ¥ζΡ©ΒΡ ±ΦδΓΘ
Έ“Ο«œ»ά¥Ω¥Θ§»Υ»γΚΈ±φ ΕΈοΧεΓΘ»ΥΡ‘ΒΡ…ώΨ≠œΗΑϊΘ®…ώΨ≠‘ΣΘ©Αϋά®ΚήΕύ±Υ¥ΥœύΝΎ≤ΔœύΝ§ΒΡ≤ψΘ§≤ψ ΐ‘ΫΕύΘ§Άχ¬γ‘Ϋ“…ν”ΓΘΒΞΗω…ώΨ≠‘Σ¥”ΤδΥϊ…ώΨ≠‘ΣΫ” ’–≈Κ≈——Ω…ΡήΗΏ¥ο10ΆρΗωΘ§Β±ΤδΥϊ…ώΨ≠‘Σ±Μ¥ΞΖΔ ±Θ§ΥϋΟ«ΜαΕ‘œύΝ§ΒΡ…ώΨ≠‘Σ ©Φ”–ΥΖήΜρ“÷÷ΤΉς”ΟΘ§»γΙϊΈ“Ο«ΒΡΒΎ“ΜΗω…ώΨ≠‘Σ δ»κΦ”Τπά¥¥οΒΫ“ΜΕ®ψ–÷ΒΒγ―ΙΘ®threshold voltageΘ© ±Θ§Υϋ“≤Μα±Μ¥ΞΖΔΓΘ
“≤ΨΆ «ΥΒΘ§»Υ≤ΜΒΪΩ…“‘”Ο―έΩ¥Ή÷Θ§Β±±π»Υ‘ΎΥϊ±≥…œ–¥Ή÷ ±Θ§Υϊ“≤»œΒΟ≥ω’βΗωΉ÷ά¥ΓΘΨΆΚΟ±»œ¬ΆΦΘ§»Υ“Μ―έΩ¥Ιΐ»ΞΘ§ΨΆΡήΗ–÷ΣΒΫΆΦΤ§÷–¥φ‘ΎΡ≥÷÷≤ψΦΕΘ®hierarchyΘ©Μρ’ΏΗ≈ΡνΫαΙΙΘ®conceptual structureΘ©Θ§“Μ≤ψ“Μ≤ψΒΡΘΚ
ΒΊΟφ «”…≤ίΚΆΥ°ΡύΉι≥…Θ§ΆΦ÷–”–“ΜΗω–ΓΚΔΘ§–ΓΚΔ‘ΎΤοΒ·Μ…ΡΨ¬μΘ§Β·Μ…ΡΨ¬μ‘Ύ≤ίΒΊ…œΓΘ

ΙΊΦϋΒψ «Θ§Έ“Ο«÷ΣΒά’β «–ΓΚΔΘ§Έό¬έ–ΓΚΔ‘ΎΡΡ÷÷ΜΖΨ≥ΕΦ»œ ΕΘ§“ρ¥Υ»Υάύ≤Μ–η“Σ÷Ί–¬―ßœΑ–ΓΚΔ’βΗωΗ≈ΡνΓΘ
ΒΪΜζΤς≤ΜΆ§Θ§Υϋ–η“ΣΨ≠ΙΐΕύ¥ΈΖ¥Η¥ΒΡ―ßœΑΙΐ≥ΧΓΘΈ“Ο«‘Όά¥Ω¥Θ§ΜζΤς»γΚΈ±φ ΕΈοΧεΓΘ‘Ύ»ΥΙΛ…ώΨ≠Άχ¬γ÷–Θ§–≈Κ≈“≤‘Ύ“…ώΨ≠‘Σ”÷°Φδ¥Ϊ≤ΞΘ§ΒΪ «Θ§…ώΨ≠Άχ¬γ≤Μ «ΖΔ…δΒγ–≈Κ≈Θ§Εχ «ΈΣΗς÷÷…ώΨ≠‘ΣΖ÷≈δ»®÷ΊΓΘ ΚΆ»®÷ΊΫœ–ΓΒΡ…ώΨ≠‘Σœύ±»Θ§»®÷ΊΗϋ¥σΒΡ…ώΨ≠‘ΣΜαΕ‘œ¬“Μ≤ψ…ώΨ≠‘Σ≤ζ…ζΗϋΕύΒΡΉς”ΟΘ§ΉνΚσ“Μ≤ψΫΪ’β–©Φ”»® δ»κΖ≈‘Ύ“ΜΤπΘ§“‘ΒΟ≥ω¥πΑΗΓΘ
±»»γΘ§“Σœκ»Ο“ΜΗωΦΤΥψΜζ»œ≥ω“Ο®”Θ§–η“ΣΫ®ΝΔ“ΜΉι ΐΨίΩβΘ§ΑϋΚ§ ΐ«ß’≈Ο®ΒΡΆΦœώΚΆ ΐ«ß’≈≤ΜΚ§Ο®ΒΡΆΦœώΘ§Ζ÷±π±ξΦ«“Ο®”ΚΆ“≤Μ «Ο®”Θ§»ΜΚσΘ§ΫΪΆΦœώ ΐΨίΧαΙ©Ηχ…ώΨ≠Άχ¬γΘ§Ήν÷’ δ≥ω≤ψΫΪΥυ”––≈œΔ——ΦβΕζΕδΓΔ‘≤Ν≥ΓΔΚζ–κΓΔΚΎ±«Ή”ΓΔ≥ΛΈ≤ΑΆ——Ζ≈‘Ύ“ΜΤπΘ§≤ΔΗχ≥ω“ΜΗω¥πΑΗΘΚΟ®ΓΘ’β÷÷―ΒΝΖΦΦ θ±Μ≥ΤΈΣΦύΕΫ―ßœΑΘ®supervised learningΘ©ΓΘ
ΜΙ”–“Μ÷÷ΦΦ θΫ–ΉωΈόΦύΕΫ―ßœΑΘ®Unsupervised learningΘ©Θ§ΨΆ « Ι”ΟΈ¥±ξΦ«ΒΡ ΐΨίΘ§ΦΤΥψΜζ±Ί–κΉ‘ΦΚΩ¥ΆΦ ΕΈοΘ§±»»γ¥”“ΦβΕζΕδ”±φ±π’β «“Μ÷ΜΟ®Εχ≤Μ «ΤδΥϊΕ·ΈοΓΘ»ΜΕχ’β–©ΖΫΖ®»ί“ΉΈσΒΦΜζΤςΘ§ΈσΑ―“ΦβΕζΕδ”Ο® Ε±π≥…ΙΖΘ§Μρ’ΏΑ―δΫ–ήΟ®Έσ»œΈΣεΏ¬όΟ®ΓΘ
ΒΪ «Θ§»γΙϊΆΦΤ§ «’β―υΒΡΡΊΘΩ

“ΜΗω3Υξ–ΓΚΔΕΦΡή Ε±π≥ωΟ®ΒΡ’’Τ§Θ§ΦΤΥψΜζΩΤ―ßΦ“Ο«»¥Μ®ΝΥΕύΡξ ±ΦδΫΧΜαΦΤΥψΜζΩ¥ΆΦ ΕΈοΓΘΙΊΦϋΨΆ «Ή‘÷ς―ΒΝΖΝΩΓΘ
÷±ΒΫ20 άΦΆ80Ρξ¥ζΘ§ά¥Ή‘Φ”ΡΟ¥σΕύ¬ΉΕύ¥σ―ßΒΡ“…ώΨ≠Άχ¬γœ»«ΐ”Geoff HintonΝλΒΦΒΡ–ΓΉιΘ§Χα≥ωΝΥ“Μ÷÷―ΒΝΖ…ώΨ≠Άχ¬γΒΡΖΫΖ®Θ§Ϋ–ΉωΨμΜΐ…ώΨ≠Άχ¬γΘ§“βΈΕΉ≈Υϋ≤ΜΜαœί»κΨ÷≤ΩœίΎεΓΘ
”Ύ ««Ω¥σΒΡΆΦ–Έ¥ΠάμΒΞ‘ΣΜρGPU≥ωœ÷ΝΥΘ§―–ΨΩ»Υ‘±“ρ¥ΥΩ…“‘‘ΎΧ® ΫΜζ…œ‘Υ––ΓΔ≤ΌΉίΚΆ¥ΠάμΆΦœώΘ§Εχ≤Μ”Ο≥§ΦΕΦΤΥψΜζΝΥΓΘ
Ά§ ±¥σ ΐΨίΒΡΦ”≥÷Θ§»ΟΨμΜΐ…ώΨ≠Άχ¬γ”Π”Ο‘Ϋά¥‘ΫΙψΖΚΓΘ2007ΡξΘ§ΟάΙζΥΙΧΙΗΘ¥σ―ßΦΤΥψΜζΩΤ―ßœΒΗ±ΫΧ ΎάνΖ…Ζ…ΆΤ≥ωΝΥImageNet——“ΜΗωά¥Ή‘ΜΞΝΣΆχΒΡ ΐΑΌΆρ¥χ”–±ξ«©ΆΦœώΒΡ ΐΨίΩβΓΘImageNetΈΣ…ώΨ≠Άχ¬γΧαΙ©ΝΥ‘Φ1000Άρ’≈ΆΦœώΚΆ1000Ηω≤ΜΆ§ΒΡ±ξ«©ΓΘ
“Μ÷±ΒΫœ÷‘ΎΘ§…ώΨ≠Άχ¬γ≥…ΈΣΜζΤς»Υ ”ΨθΒΡΚΥ–ΡΙΛΨΏΓΘΨΓΙήœ÷¥ζ…ώΨ≠Άχ¬γΑϋΚ§–μΕύ≤ψ¥Έ——Google Photos”–¥σ‘Φ30≤ψ——ΒΪΨμΜΐ…ώΨ≠Άχ¬γΒΡ≥ωœ÷Θ§»‘»Μ ««ΑΫχΝΥ“Μ¥σ≤ΫΓΘ
”κ¥ΪΆ≥…ώΨ≠Άχ¬γ“Μ―υΘ§ΨμΜΐ…ώΨ≠Άχ¬γ“≤ «”…Φ”»®…ώΨ≠‘Σ≤ψΉι≥…ΓΘΒΪ «Θ§ΥϋΟ«≤ΜΫωΫω «ΡΘΖ¬»ΥΡ‘ΒΡ‘ΥΉςΘ§Εχ «Ζ«≥Θ«ΓΒΫΚΟ¥ΠΒΊ¥” ”ΨθœΒΆ≥±Ψ…μΜώΒΟΝΥΝιΗ–ΓΘ
ΨμΜΐ…ώΨ≠Άχ¬γ÷–ΒΡΟΩΗω≤ψΘ§ΕΦ‘ΎΆΦœώ…œ Ι”ΟΙΐ¬ΥΤς Α»ΓΧΊΕ®ΒΡΆΦΑΗΜρΧΊ’ςΓΘ«ΑΦΗ≤ψΦλ≤βΒΫΫœ¥σΒΡΧΊ’ςΘ§άΐ»γœ¬ΆΦ–±œΏΘ§ΕχΚσΟφΒΡ≤ψ Α»ΓΗϋœΗΒΡœΗΫΎΘ§≤ΔΫΪΤδΉι÷·≥…÷ν»γ“ΕζΕδ”ΒΡΗ¥‘”ΧΊ’ςΓΘ
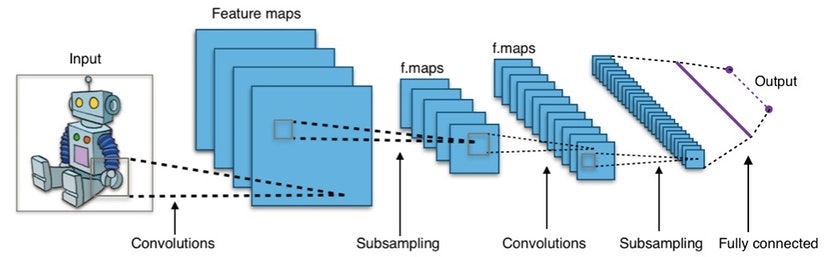
ΆΦΘΚΒδ–ΆΒΡΨμΜΐ…ώΨ≠Άχ¬γΦήΙΙ
Ήν÷’ δ≥ω≤ψœώΤ’Ά®…ώΨ≠Άχ¬γ“Μ―υ «Άξ»ΪΝ§Ϋ”ΒΡΘ®“≤ΨΆ «ΥΒΘ§ΗΟ≤ψ÷–ΒΡΥυ”–…ώΨ≠‘ΣΕΦΝ§Ϋ”ΒΫ…œ“Μ≤ψΒΡΥυ”–…ώΨ≠‘ΣΘ©ΓΘΥϋΦ·ΚœΗΏΕ»ΨΏΧεΒΡΧΊ’ς——Τδ÷–Ω…ΡήΑϋά®Ο®ΒΡœΝΖλΉ¥ΆΪΩΉΓΔ–”» –Έ―έΨΠΓΔ―έΨΠΒΫ±«Ή”ΒΡΨύάκ——≤Δ≤ζ…ζ≥§ΨΪ»ΖΒΡΖ÷άύΘΚΟ®ΓΘ
‘Ύ2012ΡξΘ§Ι»Ηη”Ο ΐ«ßΗωΈ¥±ξΦ«ΒΡYouTubeΦτΦ≠Υ謑ΆΦ≈ύ―ΒΝΥ“ΜΗωΨμΜΐ…ώΨ≠Άχ¬γΘ§Ω¥Ω¥Μα≥ωœ÷ ≤Ο¥ΓΘΚΝ≤ΜΤφΙ÷Θ§Υϋ±δΒΟ…Ο≥Λ―Α’“Ο® ”ΤΒΓΘ
ΨμΜΐ…ώΨ≠Άχ¬γ»γΚΈΫχ––ΆΦΤ§¥ΠάμΘΩΜυ±Ψ…œ”–»ΐΗω≤Ϋ÷ηΘ§ΨμΜΐ≤ψΓΔ≥ΊΜ·≤ψΓΔ≤…”Οœ¬≤…―υ’σΝ–ΉςΈΣ≥ΘΙφ»ΪΝ§Ϋ”…ώΨ≠Άχ¬γΒΡ δ»κΓΘ
Τ©»γΘ§¥”Η’Η’Ρ«’≈“–ΓΚΔΤο¬μΆΦ”Ω…“‘Ζ÷Ϋβ≥ωΘ§ΨμΜΐ…ώΨ≠Άχ¬γ±φ ΕΈοΧεΒΡΈεΗω≤Ϋ÷ηΘΚ

”Ύ «ΆΦΤ§±ΜΖ÷Ϋβ≥…ΝΥ 77 ΩιΆ§―υ¥σ–ΓΒΡ–ΓΆΦΩιΓΘ
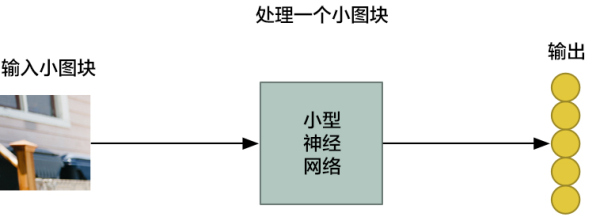
÷ΊΗ¥’βΗω≤Ϋ÷η 77 ¥ΈΘ§ΟΩ¥Έ≈–Εœ“Μ’≈–ΓΆΦΩι
»ΜΕχΘ§”–“ΜΗωΖ«≥Θ÷Ί“ΣΒΡ≤ΜΆ§ΘΚΕ‘”ΎΟΩΗω–ΓΆΦΩιΘ§Έ“Ο«Μα Ι”ΟΆ§―υΒΡ…ώΨ≠Άχ¬γ»®÷ΊΘ§“≤ΨΆ «ΥΒΘ§»γΙϊΡΡΗω–ΓΆΦΩι≤Μ“Μ―υΘ§Έ“Ο«ΨΆ»œΈΣ’βΗωΆΦΩι «““λ≥Θ”Θ®interestingΘ©ΒΡΓΘ
Έ“Ο«≤Μœκ≤Δ≤Μœκ¥ρ¬“–ΓΆΦΩιΒΡΥ≥–ρΘ§Υυ“‘ΨΆΑ―ΟΩΗω–ΓΆΦΩιΑ¥’’ΆΦΤ§…œΒΡΥ≥–ρ δ»κ≤Δ±Θ¥φΫαΙϊΘ§ΨΆœώ’β―υΘΚ
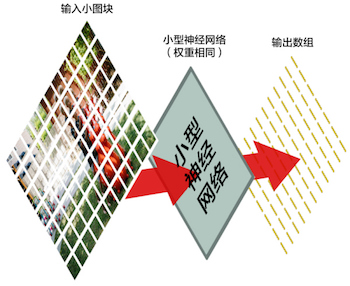
ΒΎ»ΐ≤ΫΒΡΫαΙϊ «“ΜΗω ΐΉιΘ§’βΗω ΐΉιΕ‘”ΠΉ≈‘≠ ΦΆΦΤ§÷–Ήν“λ≥ΘΒΡ≤ΩΖ÷ΓΘΒΪ «’βΗω ΐΉι“ά»ΜΚή¥σ:

ΈΣΝΥΦθ–Γ’βΗω ΐΉιΒΡ¥σ–ΓΘ§Έ“Ο«άϊ”Ο“Μ÷÷Ϋ–ΉωΉν¥σ≥ΊΜ·Θ®max poolingΘ©ΒΡΚ· ΐά¥ΫΒ≤…―υΘ®downsampleΘ©ΓΘΒΪ’β“ά»Μ≤ΜΙΜΘΓ
»ΟΈ“Ο«œ»ά¥Ω¥ΟΩΗω 2×2 ΒΡΖΫ’σ ΐΉιΘ§≤Δ«“Ντœ¬Ήν¥σΒΡ ΐΘΚ
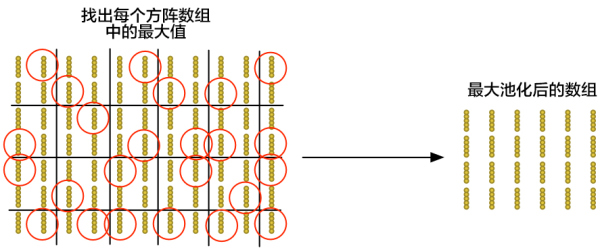
’βάοΘ§“ΜΒ©Έ“Ο«’“ΒΫΉι≥… 2×2 ΖΫ’σΒΡ 4 Ηω δ»κ÷–»ΈΚΈ“λ≥ΘΒΡ≤ΩΖ÷Θ§ΒΪΈ“Ο«ΨΆ÷Μ±ΘΝτ’β“ΜΗω ΐΓΘ’β―υ“Μά¥Έ“Ο«ΒΡ ΐΉι¥σ–ΓΨΆΥθΦθΝΥΘ§Ά§ ±Ήν÷Ί“ΣΒΡ≤ΩΖ÷“≤±ΘΝτΉΓΝΥΓΘ
ΒΫœ÷‘ΎΈΣ÷ΙΘ§Έ“Ο«“―Ψ≠Α―“ΜΗωΚή¥σΒΡΆΦΤ§ΥθΦθΒΫΝΥ“ΜΗωœύΕ‘Ϋœ–ΓΒΡ ΐΉιΓΘ
ΐΉιΨΆ «“Μ¥° ΐΉ÷Εχ“―Θ§Υυ“‘Έ“Ο«Έ“Ο«Ω…“‘Α―’βΗω ΐΉι δ»κΒΫΝμΆβ“ΜΗω…ώΨ≠Άχ¬γάοΟφ»ΞΓΘΉνΚσΒΡ’βΗω…ώΨ≠Άχ¬γΜαΨωΕ®’βΗωΆΦΤ§ «ΖώΤΞ≈δΓΘΈΣΝΥ«χΖ÷ΥϋΚΆΨμΜΐΒΡ≤ΜΆ§Θ§Έ“Ο«Α―Υϋ≥ΤΉς“»ΪΝ§Ϋ””Άχ¬γΘ®“Fully Connected” NetworkΘ©ΓΘ
Υυ“‘¥”ΩΣ ΦΒΫΫα χΘ§Έ“Ο«ΒΡΈε≤ΫΨΆœώΙήΒά“Μ―υ±ΜΝ§Ϋ”ΝΥΤπά¥ΘΚ
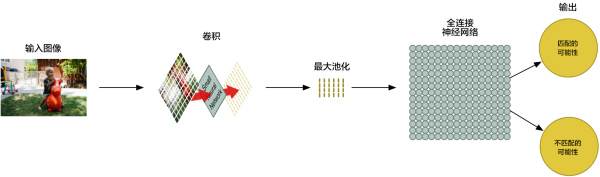
’ϊΗωΙΐ≥Χ÷–Θ§ΡψΩ…“‘Α―’β–©≤Ϋ÷η»Έ“βΉιΚœΓΔΕ―ΒΰΕύ¥ΈΘ§ΨμΜΐ≤ψ‘ΫΕύΘ§Άχ¬γΨΆ‘ΫΡή Ε±π≥ωΗ¥‘”ΒΡΧΊ’ςΓΘΒ±Ρψœκ“ΣΥθ–Γ ΐΨί¥σ–Γ ±Θ§“≤Υφ ±Ω…“‘Βς”ΟΉν¥σ≥ΊΜ·Κ· ΐΓΘΕχ…ν≤ψΨμΜΐΆχ¬γΘ®Convolutional Neural NetworksΘ©ΨΆ « Ι”ΟΝΥΕύ¥ΈΨμΜΐΓΔΉν¥σ≥ΊΜ·ΚΆΕύΗω»ΪΝ§Ϋ”≤ψΓΘΈΣΝΥ Βœ÷ΨμΜΐ…ώΨ≠Άχ¬γ”Π”ΟΘ§ΜζΤς―ßœΑ–η“ΣΖ¥Η¥―ßœΑ≤β ‘ΓΘ
¥”ΝψΩΣ ΦΙΙΫ®ΨμΜΐ…ώΨ≠Άχ¬γΘ§Ζ―«°”÷ΚΡ ±Θ§“ΒΡΎΩΣΖ≈ΝΥ“Μ–©APIΘ®Application Programming InterfaceΘ§”Π”Ο≥Χ–ρ±ύ≥ΧΫ”ΩΎΘ©Θ§ ΙΩΣΖΔ’ΏΈό–ηΉ‘ΦΚ―–ΨΩΜζΤς―ßœΑΜρΦΤΥψΜζ ”ΨθΉ®“Β÷Σ ΕΓΘ
GoogleCloud Vision «Ι»ΗηΒΡ ”Ψθ Ε±πAPIΘ§ Ι”ΟREST APIΓΘΥϋΜυ”ΎΩΣ‘¥ΒΡTensorFlowΩρΦήΓΘΥϋΦλ≤βΒΞΗωΟφ≤ΩΚΆΈοΧεΘ§≤ΔΑϋΚ§“ΜΗωœύΒ±»ΪΟφΒΡ±ξ«©Φ·ΓΘ
ΝμΆβΘ§Ι»ΗηΆΦœώΥ―ΥςΩ…“‘ΥΒ «“ΜΗωΨό¥σΒΡΆΦœώ ΐΨίΩβΘ§Μυ±Ψ…œΗΡ±δΝΥΈ“Ο«¥ΠάμΆΦœώΒΡΖΫ ΫΓΘ
’βάο”–“Μ’≈Ι»ΗηΆΦœώΥ―ΥςΒΡ ±Φδ±μΓΘ
IBMΈ÷…≠ ”Ψθ Ε±π «Έ÷…≠ΩΣΖΔ’Ώ‘ΤΘ®Watson Developer CloudΘ©ΒΡ“Μ≤ΩΖ÷Θ§≤ΔΗΫ¥χΝΥ“Μ¥σ≈ζΡΎ÷ΟΒΡάύ±πΘ§ΒΪ ΒΦ …œ «ΈΣΗυΨίΡψΧαΙ©ΒΡΆΦœώά¥―ΒΝΖΉ‘Ε®“εΕ®÷ΤάύΕχΙΙΫ®ΒΡΓΘΥϋΜΙ÷ß≥÷“Μ–©ΚήΑτΒΡΙΠΡήΘ§Αϋά®NSFWΚΆOCRΦλ≤βΘ§»γGoogle Cloud VisionΓΘ
Facebook AI ResearchΘ®FAIRΘ©»œΈΣΘ§…νΕ»ΨμΜΐ…ώΨ≠Άχ¬γ»ΟΈ“Ο«“―Ψ≠Ω¥ΒΫΆΦœώΖ÷άύΘ®ΆΦœώ÷–”– ≤Ο¥Θ©“‘ΦΑΕ‘œσΦλ≤βΘ®Ε‘œσ‘ΎΡΡάοΘΩΘ©…œΒΡΨό¥σΫχ≤ΫΘ®Φϊœ¬ΆΦaΚΆbΘ©Θ§ΒΪ’β÷Μ «“ΜΗωΩΣ ΦΘ§ΡΩ±ξ «…ηΦΤ“Μ÷÷ Ε±πΚΆΖ÷ΗνΆΦœώ÷–ΟΩΗωΕ‘œσΒΡΦΦ θΘ§»γœ¬ΆΦcΓΘ

”Ύ «FacebookœκΫΪΜζΤς ”ΨθΆΤœρœ¬“ΜΗωΫΉΕΈ——‘ΎœώΥΊΦΕ±π…œάμΫβΆΦœώΚΆΕ‘œσΓΘΆΤΕ·ΒΡ÷ς“Σ–¬ΥψΖ® «DeepMask 1Ζ÷ΕΈΩρΦή“‘ΦΑSharpMask 2œΗΖ÷ΡΘΩιΓΘΥϋΟ«Ι≤Ά§ ΙFAIRΒΡΜζΤς ”ΨθœΒΆ≥Θ§ΡήΙΜΦλ≤β≤ΔΨΪ»ΖΒΊΟηΜφΆΦœώ÷–ΒΡΟΩΗωΈοΧεΓΘ Ε±πΝςΥ°œΏΒΡΉνΚσΫΉΕΈ Ι”Ο“ΜΗωΉ®Ο≈ΒΡΨμΜΐΆχ¬γΘ§≥Τ÷°ΈΣMultiPathNet 3Θ§“‘ΤδΑϋΚ§ΒΡΕ‘œσάύ–ΆΘ®άΐ»γ»ΥΘ§ΙΖΘ§―ρΘ©Θ§ΈΣΟΩΗωΕ‘œσ―Ύ¬κ±ξΦ«ΓΘ
Clarif.ai «“ΜΗω–¬–ΥΒΡΆΦœώ Ε±πΖΰΈώΘ§“≤ Ι”ΟREST APIΓΘΙΊ”ΎClarif.aiΒΡ“ΜΗω”–»ΛΒΡΖΫΟφ «ΥϋΗΫ¥χΝΥ“Μ–©ΡΘΩιΘ§”–÷ζ”ΎΫΪΤδΥψΖ®Ε®÷ΤΒΫΧΊΕ®÷ςΧβΘ§»γ ≥ΈοΓΔ¬Ο––ΚΆΜιάώΓΘ
ΨΓΙή…œ ωAPI ”Ο”Ύ…Ό ΐ“ΜΑψ”Π”Ο≥Χ–ρΘ§ΒΪΡψΩ…Ρή»‘»Μ–η“ΣΈΣΧΊΕ®»ΈΈώΩΣΖΔΉ‘Ε®“εΫβΨωΖΫΑΗΓΘ–“‘ΥΒΡ «Θ§–μΕύΩβΩ…“‘Ά®Ιΐ¥Πάμ”≈Μ·ΚΆΦΤΥψΖΫΟφά¥ ΙΩΣΖΔ»Υ‘±ΚΆ ΐΨίΩΤ―ßΦ“ΒΡ…ζΜν±δΒΟΗϋΦ”»ί“ΉΘ§¥”Εχ ΙΥϊΟ«Ή®ΉΔ”Ύ―ΒΝΖΡΘ–ΆΓΘ”––μΕύΩβΘ§Αϋά®TheanoΓΔTorchΓΔDeepLearning4JΚΆTensorFlow“―Ψ≠≥…ΙΠ”Π”Ο”ΎΗς÷÷”Π”ΟΓΘ
-END-
<ά¥‘¥ ΘΚmindmajix.comΓΔFacebook AI ResearchΓΔmedium.comΓΔcosmosmagazine.comΘΜ±ύ“κ’ϊάμΘΚΩΤΦΦ––’Ώ>

»γΙϊΡζΖ«≥ΘΤ»«–ΒΡœκΝΥΫβITΝλ”ρΉν–¬≤ζΤΖ”κΦΦ θ–≈œΔΘ§Ρ«Ο¥Ε©‘Ρ÷ΝΕΞΆχΦΦ θ” ΦΰΫΪ «ΡζΒΡΉνΦ―ΆΨΨΕ÷°“ΜΓΘ